
Experiments with RESNET34
After many trials with resnet18 and minimal image augmentation, we noticed the loss plateaued at around 0.5 even with increased number of epochs, so we went ahead and experimented with resnet34. We saw better results from the training with more layers and more epochs in the training model. Additionally, based on our learning from resnet18 that more image augmentation seemed to be correlated to higher loss, we limited the numbers of augmentation used and also tuned down the probability of their occurrence.
For the following, momentum = 0.9, decay = 0.0005
| epoch | batch size | schedule | horizontal/vertical flip (p) | random color jitter (p) | normalize | invert (p) | final loss | 20% Accuracy | |
|---|---|---|---|---|---|---|---|---|---|
| 25 | 64 | {0:.01, 8:.001, 15:0.0001} | 0.5/0.0 | - | - | - | 0.118 | 0.8325 | |
| 25 | 64 | {0:.01, 8:.001, 15:0.0001} | 0.2/0.2 | - | - | - | 0.194 | 0.834 | |
| 32 | 64 | {0:.01, 12:.001, 19:0.0001} | 0.2/0.2 | - | - | - | 0.132 | 0.8315 |
Plots:
First Attempt with RESNET 34:
epoch = 25, schedule = {0:.01, 8:.001, 15:0.0001}, batch size = 64
horizontal flip (p) = 0.5, vertical flip (p) = 0, color jitter (p) = 0 normalize (mean, std) = (0, 0), invertion (p) = 0, final loss = 0.118
20% prediction accuracy: 0.8325
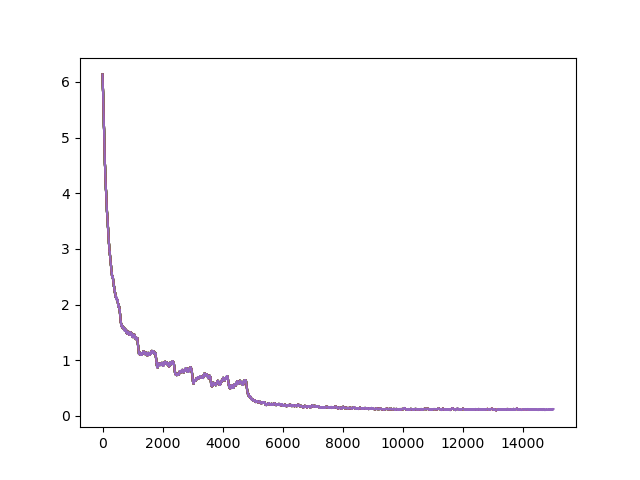
It should be mentioned we tried other values for momentum (0.95 and 0.99) and weight decay (0.0001 and 0.001) but saw no major improvements
epoch = 25, schedule = {0:.01, 8:.001, 15:0.0001}, horizontal flip (p) = 0.2, vertical flip (p) = 0.2, color jitter (p) = 0 normalize (mean, std) = (0, 0), invertion (p) = 0, final loss = 0.194
20% prediction accuracy: 0.834
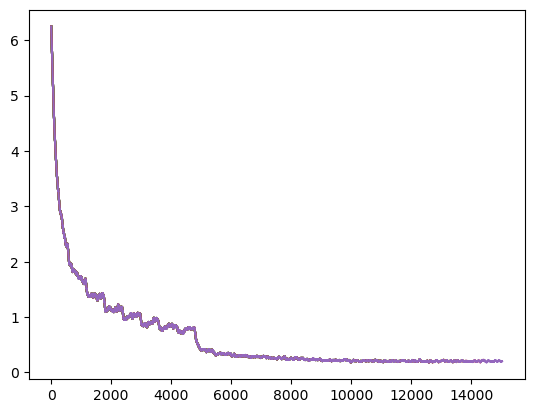
transform_train = transforms.Compose([
transforms.Resize(input_size),
transforms.RandomCrop(input_size, padding=8, padding_mode='edge'), # Take 256x256 crops from padded images
transforms.RandomHorizontalFlip(), # 50% of time flip image along y-axis
transforms.ToTensor(),
])
Reduce LR On Plateau:
It was at this point, we decided to get smarter about scheduling our learning
rate. After reading a few articles on getting out of plateaus like this one on Cyclical Learning Rates,
we came across optim.lr_scheduler.ReduceLROnPlateau which allows the model
to adjust the learning rate when it detects a plateau in the loss.
We adjusted our train function to use the new scheduler.
def train(net, dataloader, epochs=1, start_epoch=0, lr=0.01, momentum=0.90, decay=0.0005,
verbose=1, print_every=10, state=None, checkpoint_path=None):
net.to(device)
net.train()
losses = []
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=momentum, weight_decay=decay)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.1, patience=2, threshold=0.0001, threshold_mode='abs')
# Load previous training state
if state:
net.load_state_dict(state['net'])
optimizer.load_state_dict(state['optimizer'])
start_epoch = state['epoch']
losses = state['losses']
for epoch in range(start_epoch, epochs):
sum_loss = 0.0
for g in optimizer.param_groups:
print ("Learning rate: %f"% g['lr'])
for i, batch in enumerate(dataloader, 0):
inputs, labels = batch[0].to(device), batch[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward() # autograd magic, computes all the partial derivatives
optimizer.step() # takes a step in gradient direction
losses.append(loss.item())
sum_loss += loss.item()
if i % print_every == print_every-1: # print every 10 mini-batches
if verbose:
print('[%d, %5d] loss: %.3f' % (epoch, i + 1, sum_loss / print_every))
sum_loss = 0.0
scheduler.step(sum_loss)
if checkpoint_path:
state = {'epoch': epoch+1, 'net': net.state_dict(), 'optimizer': optimizer.state_dict(), 'losses': losses}
torch.save(state, checkpoint_path + 'checkpoint-%d.pkl'%(epoch+1))
plt.plot(smooth(state['losses'], 50))
plt.savefig('checkpoint-%d.png'%(epoch+1))
return losses
First Attempt with the scheduler on RESNET 34:
epoch = 35, batch size = 256
horizontal flip (p) = 0.5, vertical flip (p) = 0, color jitter (p) = 0 normalize (mean, std) = (0, 0), invertion (p) = 0, final loss = 0.056
20% prediction accuracy: 0.8135
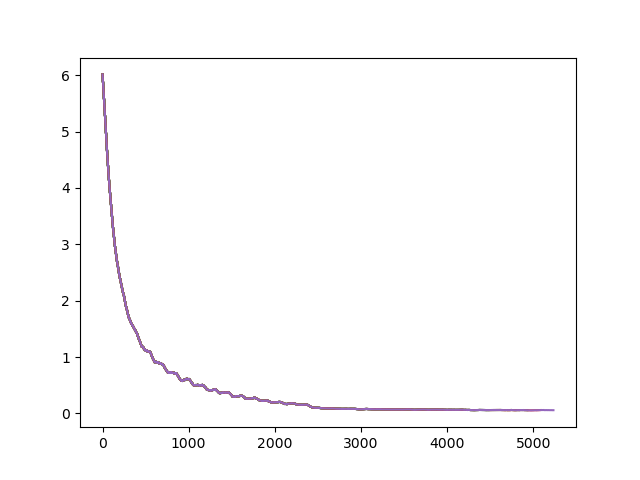
This was a slightly disappointing accuracy compared to previous runs considering that was the lowest final loss we had seen yet. Our guess is that the batch size was too high or we ended up getting overfit past in the later epochs where it plateaus. We found an article on early stopping to avoid overfit. We tested this hypothesis by submitting a prediction using the state saved for epoch 17. This had an accuracy of 0.813, not a great enough difference to support our hypothesis.